Contact me for feedback or questions! I reply to everyone.
Most of us will use these every day (usually several times, in fact), so it's important to carefully consider your selection of choices. Not only do we want great results, but - since we will often share some really sensitive data with them (such as medical, travel, or even that we're interested in loli or shoplifting) - they better not be doing dirty stuff with it. There are also various additional functions that we'd like our search engines to provide. Now why did I use the phrase selection of choices? Because - as you will see - the situation with search engines is not as good as with E-mail providers, so we're forced to switch around since there isn't a single one that has everything we need. Without further ado, let us check what is available:
A while after finishing this article I've had a "revelation" - the situation with search engines is even worse than I thought before. Aside from Wiby (which has very few searchable sites in it) and Mojeek, the search engines mentioned here depend on others for their results. By "others" I mean either Google, Bing or Yahoo - three massive privacy violators. When you search through, say, Swisscows - the query is first sent to Swisscows, which forwards it to Bing, which then returns the result to Swisscows and finally to you. There are several problems with such a setup:
This is not that different from using Invidious, Nitter, Facebook Container or custom Discord clients for their respective services - the violator still calls the shots. And we - like the wives dependent on their abusive husbands - keep coming back for more in hopes we can prevent some of the damage. But - as we rely more and more on the violators - it gets harder to dump them. Keep this in mind while reading through the below recommendations.
SearX is an open-source proxy for search engines (mostly violators such as Google or Bing, but also Mojeek and others) that anyone can run on his own machine. Some instances include Snopyta's (onion), Disroot's and searx.me (warning: not all of them necessarily support your privacy). The whole point of SearX is to choose which engines you want to use for the results, without
sending the requests directly to them. Problem number one: the instances are often blocked by the engines themselves. Number two: the results are often very weak despite choosing big providers.
Three: the results are mixed in weird ways, such as a full page of results from a single engine, or the same result repeated a few times. All these problems seem to depend on the instance used.
SearX used to have an extremely annoying bug where the results didn't go beyond first page, but doesn't seem to anymore and still does, fuck it (but again, depends on instance,
settings, time of usage...some instances don't seem to have that problem). Here's snopyta's instance privacy:
What data do you collect? - We collect as few as possible. For example, we don't log ip addresses or search queries you make with searx.
And Disroot's:
No data (IP address, session cookie etc) is stored on the server, unless for troubleshooting purposes, after which the log data is purged from the server.
Now, these two instances are not very good in terms of usability (they suffer from search engines going down often, as well as the dreaded "no results beyond first page" issue). Inspect the instance list to perhaps find a better one.
The available search categories are General, Files, Images, IT, Map, Music, News, Science, Social Media and Videos (the most out of any engine listed here) - and you can choose which search providers (over 70 available) are used to display the results for any of them. There are many other options like enforcing HTTPs, removing trackers from returned URLs, changing the theme, content filtering, etc. SearX is also integrated with the Wayback Machine - this means you can check out the sites without connecting directly to them, even if they are not available anymore. The service does not require JavaScript for its functionality at all - you can even save settings through a bookmarked URL without either JS or cookies enabled.
Summary: possible to search without JS (though will miss some functionality); can search through pretty much all relevant engines; has web archive integration; can be private or onionified depending on instance. Relies on the violators to receive its results - and the image ones particularly suck (regardless of provider choice in settings) for some reason. Still, it's probably the best choice out there right now, if you find a good instance - just use something else for images.
UPDATE: it's worse than I thought - keep reading! If we only took into account the privacy policies (archive), this little known search engine from the Swiss Alps would rank very highly indeed:
We do not collect any of our visitors’ personal information. None whatsoever. When using Swisscows neither your IP address is recorded nor is the browser you are using (Internet Explorer, Safari, Firefox, Chrome, etc.) collected. No analyses are made, which operating system our users use (Windows, Mac, Linux, etc.); your search are not recorded either. We record absolutely no data from our visitors. The only information we store is the number of search requests entered daily at Swisscows, to measure the total overall traffic on our website and to evaluate a breakdown of this traffic by language and mere overall statistics.
No IP or browser data is stored! Swisscows even realizes (unlike, say, DuckDuckGo) that saving the search queries is also dangerous, even if allegedly disassociated from so-called personal information:
Furthermore, it is important not to store any search terms, given that these can also contain personal data. (Just think about someone who enters their own name and/or their insurance number into the search box.)
For a while I thought that - while they might not store anything themselves - they might still share some data with Bing (which they use for their results) - but my suspicions were defused:
Swisscows does not transmit any personal information to third party search engines or to the providers of sponsored results.
All of this is according to their privacy policy only. However, we know better than to believe a privacy policy blindly - especially when there are some problems with the trustworthiness of Swisscows. First of all, they require JavaScript to display the page at all - which is a terrible design; worse yet - the code is heavily obfuscated - almost as if they were hiding something. I got a report of Swisscows including redirect links in its results. At first I thought it's some mistake, but decided to investigate and confirmed it. They look like this:
http://www.smartredirect.de/redir/clickGate.php?u=[UniqueUserId?]&m=12&p=[YetAnotherID?]&q=[YourSearchQuery]&url=[TargetURL]&r=https%3A%2F%2Fswisscows.ch%3Fquery%3D[YourQuery]
Shady as fuck and contrary to their privacy policy of not sending your data anywhere - because that redirect service will absolutely get your browsing history with a what seems to be a user ID (unconfirmed yet) attached to it; as well as the search engine you used (in this case, Swisscows - but who knows what other partners in crime they have). According to this stat site (archive), Smart Redirect seems to collect the browsing history of almost 20K different people every day - a pretty significant violator, then. What this service actually does is show sponsored results that are indistinguishable from the regular ones aside from a little image next to them (for which Swisscows makes another third-party request). If you click on those links, your browser will make a request to an affiliate marketing company such as awin or linksynergy - which also seem to contain unique user IDs. Sometimes, searches from the Tor network will be denied - this might depend on which exit node you get. Regardless, they lied about not sending your data to third parties - safe to say, then, that the myth of the little private Swiss Cow is dead and buried. But let's dig a little deeper:
The only legitimate reason for our beginning to collect personal data would be the existence of a legal warrant or a court order, which would require us to do so in connection with a specific user, who is suspected of such a serious crime that such a violation of his or her privacy would be justified.
So they will perform targeted surveillance without notifying you when the government comes knocking (that's the great Swiss Privacy Law in action). The search engine also has this "family-friendly" shtick, which means you might get a message such as:
Dear user, the entered word is not allowed for under 18 year olds, since we have decided on the protection of minors, the word "insert search term" is excluded from the search. Thank you very much for your understanding!
This is activated by many porn-related queries and some violence-related ones but you can still find really graphic stuff like people's limbs being cut off pretty easily. And thankfully, information alone does not seem to be censored.
Swisscows also has a semantic map
feature which displays additional terms relevant to the search you've typed, narrowing the results to what you might be looking for. I haven't found
it very useful though, or maybe I just don't get how to use it. The search engine does not run without JavaScript enabled at all (can only see a white background - bad design!). XHR is also
required to display the actual results (which come from Bing exclusively). Used to not work in Pale Moon but that seems to have been fixed recently (whether by them or by PM...). Swisscows can
search for images, videos, and news; it also includes the only (AFAIK) privacy-aware translator which is unfortunately also family-friendly (cannot translate swear words...) does not
include the translator anymore, so the one thing it was useful for is gone. Of course, the Swisscows Privacy Wall came crashing down above; it's not a sure thing we can even trust its policy
when they've already broken it. So, Bing might be getting your data after all. Having problems with Tor seals the deal even further. Another one bites the dust, as they say!
A privacy-based proxy for Google search. Claims to believe privacy is a fundamental human right
; let's see how much do they actually follow that belief:
Why we don’t collect any "personal data"
We saw the perils of that in DDG's section - where, for example, measuring engagement of specific events on the page
was considered non-personal, along with the actual search
queries. But let's give the benefit of doubt and see what is StartPage's interpretation of the term:
We don’t record your IP address
With the most important potential roadblock out of the way, the privacy train is running at full speed!
We don’t serve any tracking or identifying cookies
No hiccups so far.
We do measure overall traffic numbers and some other – strictly anonymous – statistics. These stats may include the number of times our service is accessed by a certain operating system, a type of browser, a language, etc.
The privacy train is slowing down. I spoke of the problems with so-called anonymous data in DDG's section. Remember: the only anonymous data is no data
. But it gets worse. StartPage
includes advertisements from Google (these cannot be removed by uMatrix, only element hiding) on top of their search results page, and:
In order to enable the prevention of click fraud, some non-identifying system information is shared
Aaand the privacy train has been totally derailed! Now you have to trust StartPage's determination of what is non-identifying
enough to be safe in Google's hands. Now they don't say
exactly what that data consists of - but if it's the same set mentioned above that StartPage uses for their statistics, it would definitely leave the possibility of revealing someone thanks to
browser fingerprinting. So StartPage sends potentially identifying data to Google. It's not all that bad though - at least they apparently don't store it themselves. And then there's this:
Any request will have to come from Dutch judicial authorities. We’ll only comply if we’re legally obliged to do so. But we’re not likely to receive requests by governments to hand over user data – simply because we don’t have any.
And:
We will never comply with any voluntary surveillance program
So it seems that, at least - you're pretty safe from the government's prying eyes. The other issue with StartPage are the absolutely terrible search results. That is
because Google runs a massive
censorship campaign (archive), deranking any alternative or conspiratorial content. This means you will even get results that don't relate
to your query at all - and I've confirmed it with tests. Try searching for something like "was the Christchurch shooting faked" and you will see what I mean. Then compare with Qwant
or DDG. I did this for many other queries which would result in displaying alternative or conspiratorial websites (if the search engine was honest, that is), but instead showed me irrelevant
trash. Also, just like Google, it supports no other ways to search aside from Web and Images. StartPage works perfectly with JavaScript disabled and has the handy Anonymous View
feature, allowing you to visit returned sites without revealing yourself to them (however, much functionality will be disabled).
Interestingly, a long time ago StartPage used to run a search engine called IxQuick that used their own index. I used that extensively when it was around and the results were pretty good
AFAIK. Why did they take it down and submitted completely to the Google botnet? We could have had an actual privacy-based search engine with no dependency on the tech giants
and no censorship (since StartPage doesn't seem to believe in it, unlike Qwant). But with the situation as is, I cannot recommend StartPage at all due to the censored results
and sharing your system data with Google. Use only for emergencies when you really need Google's huge web index. UPDATE: actually, fuck that. StartPage
just literally got bought by an advertising company (archive) and also ran a Mozilla-esque PR piece (archive) defending the acquisition. UPDATE
November 2020: now they became totally authoritarian, hating TOR, VPNs and even private browsers
:
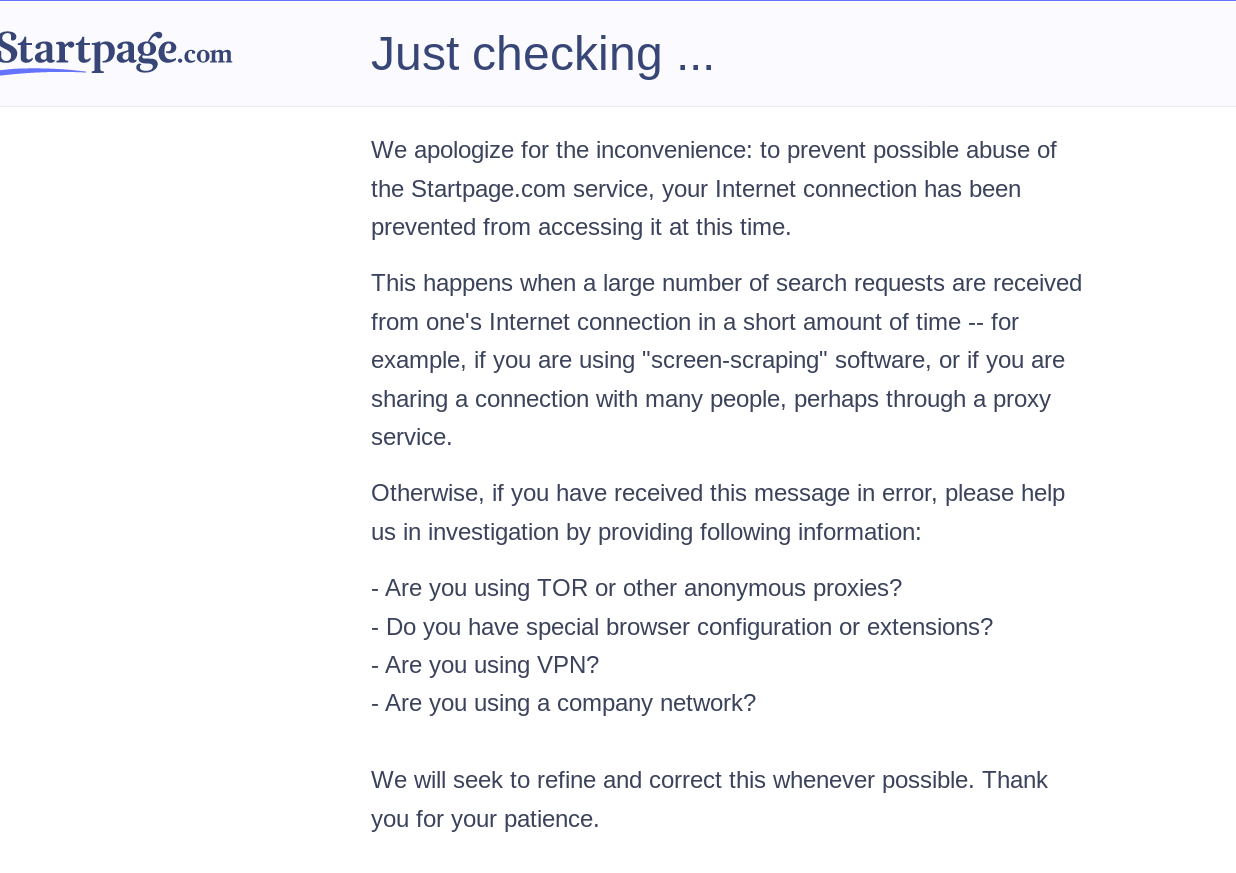
This reminds me of malicious Cloudflare browser checks, where they compare your setup to what they consider "safe" to decide whether to let you through. I found this out in November, but it's
probably been around since earlier. To be honest, I've always felt something was off about these guys; their image was "too clean" if you know what I mean. Now we have proof that for them, privacy
has only served as a useful slogan; they never actually gave a shit about it. Therefore, I can honestly advise to avoid these frauds completely now!
An interesting new search engine dedicated to lean, personal, old-school websites. Really recommend keeping an eye on that one - and you can literally support the creation of a better Internet by submitting websites to it (if you know a good one, you should really do that). No big corpos allowed here! Does not require JavaScript (actually, there is not a single script on its page). Keeps logs for 48 hours (archive), though.
The search engine that doesn't track you!
Or at least, that is what it claims. The marketing is slick and I must admit I fell for it initially and was a fan for a long time - but to
be honest, there were always red flags. DuckDuckGo hosts a a privacy site (archive) with some great guides. They've refuted (archive) myths (archive) and went after giants
like Google (archive) - always a plus in my mind and a huge reason to consider a provider trustworthy. Their Twitter account posts privacy stuff all the time, etc. At a glance, DDG appears as just a
group of people like you and me, looking to protect their privacy and creating a service to do so (unlike Mozilla's in-your-face manipulation). Unfortunately, like the great magicians they are,
they've made a really convincing illusion - but still an illusion; and I will show just how.
As I said, the red flags were always there. Gabriel Weinberg - the DuckDuckGo founder - used to run the Names Database, a social network allowing you to reconnect with your old friends from school. However, the most important feature - sending messages - was locked behind a paywall which could be bypassed if you invited 24 people to the network. They claimed that you could remove yourself from the database if you wanted to:
We enable people to remove themselves from The Names Database at any time, which instantly and automatically deletes any personal information associated with the profile removed from The Names Database.
However, the service did not really respect the user:
(e) The Terms may be modified only by Company posting changes to the Terms on Website. Each time User accesses Website, User will be deemed to have accepted any such changes in effect at the time of access.
Just by visiting the website you've accepted all its terms (what if they've included a line "we can kill you in your sleep") while you weren't looking? Haha.
(a) Company owns all information submitted to it, regardless of who or what submits it, what is submitted, or how or why it is submitted. Such information includes but is not limited to any and all information submitted by User or about User and any User Information submitted during membership or through the normal use of Website and the services available through it.
(b) Any successors or assignees of Company will by default acquire for their own use, in accordance with the Terms, all information collected by Company, including but not limited to all information associated with Website as specified in section 2(a) above.
So everything you submitted there ceased to become yours (or even if someone else posted your personal info), and could have been transferred to any other company. Later versions of the agreement contained even more egregious stuff such as:
Opobox reserves the right (but not the obligation) to remove or edit Your Information
you may NOT [...] (e) "meta-search" any Opobox Web Site; (f) forge headers or otherwise manipulate identifiers when communicating in any way with the Opobox Web sites [...] (j) use data mining or any data gathering or extraction tools; (k) copy, reproduce, modify, create derivative works from, distribute or publicly display any content (except for Your Information) from the Opobox Web Sites;
So I can't change my user agent; use wget, httrack or curl; or even take a screenshot of the site. Funny shit. And this is all stuff that the later DDG founder agreed to. Then he sold the database to another company, Classmates.com (archive), which added this to the agreement:
By registering on the Opobox Web Sites, as an added benefit you will also be automatically registered on Classmates.com, which is owned and operated by Classmates Online, Inc. ("Classmates"), Opobox's parent corporation. To complete this registration on Classmates.com, you consent to have Your Information provided to Classmates by Opobox. Classmates services are provided pursuant to its own Terms of Service and Privacy Policy.
So the privacy guru that later founded DuckDuckGo sold all your data to an even more unethical company (archive). Did he have a sudden change of heart and created the uber-privacy-respecting DDG? Let's check it out:
DuckDuckGo used to claim in its privacy policy that no cookies are used by default, but some years ago it turned out they were setting a cookie from a third party, contrary to their policy. It was only on their help page and they fixed it quite fast. So is that all I've got? A cookie from ages ago?
In their Privacy Policy (archive) they proudly
proclaim, in big letters, that they don't collect or share personal information
. The big question here, of course, is what is meant by personal information
. It turns out that,
for DuckDuckGo at least, search queries alone are not personal - even if you search for something only you could know. I'm pretty sure most people would disagree with that.
DuckDuckGo claims that it is fine if you don't store the user agent or IP address along with the search, though:
We also save searches, but again, not in a personally identifiable way, as we do not store IP addresses or unique User agent strings. We use aggregate, non-personal search data to improve things like misspellings.
What this non-personal search data
consists of, is of course not stated. Is it really only the search queries DDG saves? We do know that, for example, DuckDuckGo tracks Pale
Moon usage through a parameter in the search query (?t=palemoon
), which is there by default. This also likely happens for their other partners (archive). Is that not already personal? Could it not be used to link your searches? The funny thing is, DuckDuckGo has spent much of their privacy policy criticizing Amazon for leaking their search queries (archive), which
were able to be linked to single users because they fucked up their anonymization. Can you ensure this also couldn't be done for DuckDuckGo's saved searches? After all they do track other
information as I've shown earlier. As DDG itself says (archive), The only truly anonymized data is no data
- so why not just not store the search queries? From the techcrunch article:
The most serious problem is the fact that many people often search on their own name, or those of their friends and family, to see what information is available about them on the net. Combine these ego searches with porn queries and you have a serious embarrassment. Combine them with “buy ecstasy” and you have evidence of a crime. Combine it with an address, social security number, etc., and you have an identity theft waiting to happen. The possibilities are endless.
How long does DDG store the search queries? That is not explained! They do admit they will comply with court ordered legal requests
. What could law enforcement do if they came across
queries that only I could have searched for? Could those be used against me? No idea but I'd much rather not have that happen! Then, DuckDuckGo admits to running experiments on their users (archive):
First, you might notice that when you search DuckDuckGo, there may be an "&atb=" URL parameter in the web address at the top of your browser. This parameter allows us to anonymously A/B (split) test product changes we make to DuckDuckGo.
Second, we measure engagement of specific events on the page (e.g. when a misspelling message is displayed, and when it is clicked). This allows us to run experiments where we can test different misspelling messages and use CTR (click through rate) to determine the message's efficacy.
For example, our browser extensions and mobile apps will send an atb.js request with each search made. These requests allow us to count approximately how many devices accessed DuckDuckGo
That's quite a lot of information, and right after criticizing so-called anonymous data collection! This is exactly what I've criticized Mozilla for doing and in fact what prompted me to rewrite this whole section (and article). Gabriel Weinberg has shown himself to be hypocritical and broke trust on many occasions. For a recent one, he has put his shirt selling service behind Cloudflare (a MITM) without notifying the buyer in any way. So what's the final verdict on DDG?
Looking only at the surface, you could still put it in high tier - there's no IP storage nor most of the other data search providers usually collect. Third party requests are not made. There is a JS-free version (results don't go beyond first page) and they do host a Tor hidden service (which blocks non-TBB browsers - tested with Iridium). For the non-privacy relevant stuff: the search results are really fucking good; Bing and Yahoo are used for them, as well as their own crawler. More than that - DDG displays "instant answers" from over than 400 different sources in the top right corner of the window. Has ads that can be disabled in the settings. In addition to regular sites, DDG can search for images, videos (YouTube results only) as well as news. However, digging deeper shows several serious issues with the founder's lack of reliability and trustworthiness. He clearly does not truly care about you or your privacy - as the recent Cloudflare inclusion shows. Being the great businessman that he is, he has pretended very effectively that he does and took great advantage of the recent privacy scares. So, if you care only about pure privacy / functionality, DDG is pretty good still - but due to the shaky ethical foundation and enough cracks if you look hard enough, I cannot recommend it as enthusiastically as I did before. You could say it's the Tutanota of search engines - good enough as an entry point, but you can do better. There is nothing out there even approaching the level of RiseUp's email service, though; so DuckDuckGo remains a viable option for regular usage still.
Forget the privacy - this search engine has two major flaws; first of all, it throws you a captcha all the fucking time if you use anonymizers. Second, it will randomly eat your search queries typed through the plugin or when it throws you the captcha, so you will have to retype. It's barely usable, but read further if you want to know more about it.
A French engine that claims to be fully private (archive):
We never try to find out who you are or what you are personally doing when you use our search engine.
As a principle, Qwant does not collect data about its users when they search. Plain and simple.
The above policy would be just perfect if it was followed. But it doesn't seem to be:
We don’t collect and we don’t store any history or your searches. When you search, your query is instantly anonymized by being dissociated from your IP address, in accordance with what the French data controller advices.
If we carefully analyze this vague (on purpose?) wording, we can see that it does leave the possibility of IP and search query storage. After all - if they did not store
them - what exactly is being dissociated from my IP address
? And if they don't store the IP, the queries would have nothing to be dissociated from. Of course, the other interpretation
is that they don't actually store any of that. Assuming these are French people, there is a possible language barrier here. However, it should have been easy to just say "we do not store your
IP address or search queries AT ALL". But they didn't - why didn't the French data controller
advise them of this if they do not in fact do it? Again, I might be overanalyzing this,
but the privacy policy does not make it 100% certain that this data is not stored.
Another advantage of Qwant is the usage of their own site index:
We continue our efforts to index all the Web diversity. Our crawlers relentlessly visit the global Web to refine our results.
They admit they have not fully indexed the Internet yet, so you will get results from Bing to complement Qwant's own. But we should expect Qwant to eventually finish the job (The shift towards total independence is therefore progressive, and
this is indeed the direction taken by Qwant, difficult to see from the outside!
), and then, we will have an actual search engine that does not send its requests anywhere
else, preventing Microsoft, Google or other violators from laying their hands on our search queries, being able to block Qwant or censor the searches. Speaking of censorship, Qwant claims to be unbiased (archive):
Qwant allows the whole Web to be visible without any discrimination and with no bias. Our sorting algorithms are applied equally everywhere and for every user, without trying to put websites forward or to hide others based on commercial, political or moral interests
And from their philosophy page (archive):
Qwant presents the reality of a complex world, with diverse opinions, which make it rich and worth living.
However, contrary to the above, they have inexplicably signed a censorship agreement (archive). Not only that, they allow reporting of content (archive):
In the event that you notice content that may relate to apologies for crimes against humanity, provocation to or apologies for acts of terrorism, incitement to racial hatred, towards people on the basis of their sex, their sexual orientation or identity or handicap, child pornography, incitement to violence, attacks on human dignity, when browsing the Services, you have the option to let us know
And - even though I could not detect any censorship through my tests - they do confirm that the removal of certain results is possible:
When requesting that a content be delisted on QWANT, if you obtain a positive answer from our side
So, we should consider this a censorship-friendly engine. What are some other peculiarities of Qwant? It can search for images, news, videos (YouTube only), shopping (no results?), social sites (Twitter only) and music in addition to the regular web. JavaScript version is slow and breaks Pale Moon sometimes, but there is a JS-free one available as well (though that one will lack the handy Instant Answers). August 2020 update: now shows zero results, so the only option is the JS one. Has a privacy-respecting Maps functionality! Unfortunately no Anonymous View a'la StartPage or a Tor domain.
What is the verdict, then? Great if unclear privacy policy (trying to assume the best intentions here...), mostly using own index and not requiring JavaScript are pluses. Kind of lacking search results (in the other categories, at least), no proxy or Tor and potential censorship are minuses. I would avoid it in principle just because of the latter, but the pluses (which are not found together anywhere else except Mojeek, whose index and privacy are both way weaker) might outweight it for some. Most importantly, anonymizer blocking and search queries not going through make Qwant not worth the trouble.
This one from Germany also advertises itself as private, but it not only stores your IP...
For this purpose alone, we store the full IP address and a timestamp for a maximum of 96 hours
...but also shares a part of it with advertisers:
To receive this advertising, we give the first two blocks of the IP in connection with parts of the so-called user agent to our advertising partners.
Then, their website collects and stores the following data for up to one week:
Your IP-Address, Name and URL of the retrieved file, Date and time of access, The referrer you sent, The user agent you sent
So, as we can see, MetaGer is not so great for privacy. A later section says this:
When using the MetaGer plugin, the following data is generated:
IP-Adress: Will not be stored or shared.
User-Agent: Will not be stored or shared.
It would be easy to assume that searching through the MetaGer plugin (unlike their site) stores no logs, but that would be naive and wrong. In fact, the first sentence of the Accumulating
data by context
section disconfirms this interpretation:
When using our web search engine MetaGer via their web form or through their OpenSearch interface, the following data is generated:
And then comes the stuff about IP storage and everything. So, all the above means is that the plugin usage stores no additional data over what the site itself already does. So, MetaGer's privacy is not that good, but at least you do get a maps service that stores no logs:
When using the MetaGer map service, the following data is generated:
IP-Adress: Will not be stored or shared.
User-Agent: Will not be stored or shared.
Search query: Will not be stored or shared.
Location data: Will not be stored or shared.
The search results come from Bing and Scopia, the latter of which gives absolutely terrible ones (I think this might be MetaGer's own crawler - you can turn it off and rely on Bing only).
Only has categories for regular sites, images and shopping (which brings up results from some useless Keikoo
site). Works great with JavaScript disabled but you can't save settings
without cookies (there isn't much point to configuring it at all though - really, just the Safe Search if you care about that). There is no Instant Answers like with DDG or Jive. Includes a
proxy through which you can view the returned websites anonymously, and has an onion domain (which requires solving a
captcha on anything but the Tor Browser). These two features are the only reasons to use MetaGer at all; otherwise it suffers from weak privacy and weak search results - two of the
main things we care about when rating a search engine. At least, their policy is clear, concise and contains no unnecessary posturing, which is commendable, I guess.
Another one with seemingly zero logging - we don't store your search terms, ip address nor information about your browser.
- and even has a Tor domain. Supports searching only for regular sites (results sourced from Yandex - very high quality
according to my short testing) and images (on the other hand, these suck). Provides Instant Answers similar to DDG and SearX, as well as proxy links (with JS stripped out to
prevent tracking and deanonymization). As with Ecosia, MetaGer and StartPage - relying on a single source for the results, regardless of its quality, is subject to eventual bias and censorship.
That, as well as absolutely zero customizability (can't change the basic, ugly default theme, or even turn off autocomplete) means it's probably worse than DDG. Edit: bumping it down since the
amount of results is being cut off for some reason. Apparently the engine itself contains much more functionality - but the actual instance sucks, and that is what I'm rating.
The only one using entirely their own crawler - and it's visibly reflected in the weak search results. For example, specific technical or scientific answers often won't be
found. However, you do avoid Google's (and to a lesser extent Bing's) deranking of alternative content (archive) and the unjustified promotion of mainstream big corpo media. Mojeek's privacy
isn't all that great - logs contain the time of visit, page requested, possibly referral data, and browser information
; no duration is specified. At least there's no third party
sharing and IP addresses are not stored - though this used to have a caveat:
a search query is deemed related to illegal and unethical practices relating to minors, then the full log including visiting IP address will be kept and gladly handed over to any official authorities that ask
The quote has been recently removed from the privacy policy (archive), so I assume there's no more targeted surveillance. They also say they've only put that up just to scare the CP enthusiasts and the snitching policy never actually existed, but who knows how much we can rely on that. Still, maybe we should give them the benefit of doubt until a RiseUp-like fiasco happens.
Despite the weak search results - this engine deserves consideration for being the only one with its own index that even remotely cares about your privacy. Another point in its favor is that JavaScript is not required at all even for images. I used to kind of dismiss Mojeek because I assumed they'd report you for any search query they don't like, but maybe I overreacted about a CP-only policy that's now been removed anyway. Mojeek does still ban queries for CP and the CP sites cannot be found in its index (which is what every other engine does, anyway - in addition to much more meddling / censorship). All in all, we finally do have an independent search engine that's relatively private and doesn't censor alternative content.
UPDATE June 2021: now Cloudflared, and therefore useless. Their claim to fame has been planting trees for every 45 searches (that's an average) you make using their service - but this, of course, relies on Bing ads being displayed (and I doubt it
can counter the rampant deforestation, anyway). It's not very private by default - For example, when you do a search on Ecosia we
forward the following information to our partner, Bing: IP address, user agent string, search term, and some settings like your country and language setting.
However, it claims to respect
the DNT header: If you have "Do Not Track" enabled in your browser settings we do not collect any analytics data. Most other websites ignore this setting - we think users should have a
choice.
Is the IP address apart of analytics data? Depending on how literally the DNT information is interpreted, Ecosia can become a pretty good choice, combining ethics and privacy (okay, this clearly isn't relevant now after Ecosia became Cuckflared). You
can search for regular sites, Images, Videos, News and Maps. However, the search results are sourced exclusively from Bing. Will work without JavaScript but the images will not be displayed at
all.
An allegedly private one with a not-so-good privacy policy (last updated 2 years ago...). It proudly proclaims several times how it doesn't store information in a way that can identify you
(can you be any more vague), however the myth that this is a privacy-respecting practice has been busted (archive). And they don't actually say what they DO store and for how long - an indirect
admission that they do store quite a bit of data indeed. Then comes this gem: Oscobo uses cookies to determine the effectiveness of our own marketing campaigns
. And the funniest thing
is I don't see any cookies being set in my uMatrix (outdated privacy policy, as mentioned before; however, it does show they did that at one point, or at least planned to do so). Then it says:
Oscobo uses proprietary technology to hide you search history from others who may use your device after you search. This may save you from some embarrassing situations
But I see the
search queries in my browsing history, plain as a day - so this claim was a mistake too (and a negative one this time). Oscobo can search for images (flickr only - almost useless), videos and
maps (embedding google directly, yawn); it doesn't require JavaScript but images won't show up then. Anyway, due to the issues mentioned earlier, this search engine does not seem trustworthy at
all, and I don't recommend it. It has nothing over the more widely known ones and for something even funnier, it contains a direct link to some shady "Oscobo Browser" executable file. Haha -
avoid.
To work properly, this one needs all of cookies, JavaScript and XHR enabled. What do you get for that? Let's check out their privacy policy (archive):
Discrete Search does not track search history in any user identifiable way.
The big lie of so-called private search engines rears its ugly head again. The reply is the same as to Oscobo - "user identifiable" is vague and often includes a lot of information that can reveal you if put together (archive). Why not just mention what the fuck do you store and let us decide whether we're comfortable with it? Graciously, Discrete Search DOES provide that information later (unlike Oscobo):
Additionally, we store aggregated search data to improve product performance, but never store IP addresses or unique user identifiers in connection with such searches in order to ensure that none of the information collected in connection with your search activity is personally identifiable.
So aggregated search data
is logged; the important part comes next though. If you read between the lines, they admit that they do store your IP address as well as
unique user identifiers
, just allegedly unconnected with search queries. And that is what you call private? No thanks! Why rely on someone's dubious "unconnecting" when they could just
not store the data? And Discreet Search does seem to store a lot of it, increasing the risk. Then there's this gem from the TOS (archive):
You certify that you own all intellectual property rights in Your Content. You hereby grant us, our affiliates, and our partners a worldwide, irrevocable, royalty-free, nonexclusive, sub-licensable, license to use, reproduce, create derivative works of, distribute, publicly perform, publicly display, transfer, transmit, distribute, and publish Your Content and subsequent versions of Your Content for the purposes of (i) pursuing our business interests, (ii) distributing Your Content, either electronically or via other media, to third parties seeking to download or otherwise acquire it, and/or (iii) storing Your Content in a remote database accessible by third parties. This license shall apply to the distribution and the storage of Your Content in any form, medium, or technology now known or later developed.
TL;DR everything you submit or transmit to the engine becomes theirs (not just queries but stuff like the headers your browser sends), and they are going to store it in unspecified third party databases. Ha ha. Discrete Search puts fucking image ads on top of your searches - a practice I've never seen anywhere else. At least they've fulfilled the promise of encrypting your searches locally, unlike Oscobo (yeah I've checked). Still, avoid this trainwreck.
Claims to be Protecting Your Privacy Since 2009
on its main page. If you read their privacy policy, it all checks out - Gibiru stores no logs or cookies. Of course, what they've
neglected to mention is that they literally use Google directly for their results (without proxying them, like StartPage does or Scroogle used to). Gibiru will not work
without enabling Google scripts, and so all the data that it allegedly doesn't collect, Google will happily take instead. Unfortunately - as you can see - search engines have their fair share
of frauds too. Avoid!
When I learned of Peekier after rating some less-than-stellar search engines, I was delighted to finally find another one that respects the user. There is no IP storage, no third party requests, no logging the data your browser sends (aside from temporary search queries - same policy as DuckDuckGo). It also has the handy feature of displaying the resulting website without visiting it - showing you the relevant information in an efficient way. And then I see this:
Cloudflare, our caching provider, may use a single session cookie for anti-DDOS measures.
Okay, so while YOU might not store anything, Cloudflare - hiding in the shadows between you and me - will happily take it all. And this claim, then, becomes a lie:
SSL/TLS is enforced throughout the website. No unencrypted information is transmitted over the internet.
Because Cloudflare decrypts the request on their servers, it cannot be said that the information is encrypted for its whole journey. Since Cloudflare might be the biggest current Internet evil (archive), I cannot just let this seemingly small point
slide. Of course, Peekier also claims it does not use cookies in any way to track you or store personally identifiable data
, but it does require a Cloudflare cookie to work (which is
literally a tracking cookie), as well as enabling JavaScript. And that, my friends, ruins a search engine that could have topped the list.
I wasn't supposed to review any more search engines, but this one is doing such a great Mozilla impersonation (pretending to be private with the reality being otherwise) that I just had to do this writeup. To be honest, I have never heard of FindX and likely would not have if a reader didn't mention it to me - but the level of its privacy fakery is so great that it deserves a proud spot as the last entry in this report. Let's check out their About page (archive) first:
Findx is a search engine for users who value privacy. We do not collect information about you when you perform searches, unlike most other search engines. Please read the details in our Privacy Policy. If you worry about companies creating invisible profiles of you based on your searches and internet browsing habits - Findx is for you.
The other stuff in there is not very relevant. Remember the above quotes while we inspect their Privacy policy (archive). It starts with the usual GDPR stuff, but interestingly, it seems to try to squirm out of, or not explain properly, many of those rights you allegedly have. For example:
You can request that we restrict usage of your personal data. We are only required to comply in certain circumstances.
And from Section 9:
We may ask you for additional information to confirm your identity and for security purposes, before disclosing the PII requested to you. We reserve the right to charge a fee where permitted by law, for instance if your request is manifestly unfounded or excessive.
Now compare the above with how Qwant treats GDPR (archive). But since I don't put much value into these laws at all, let's move on to the more
important sections - namely 3.2 Findx Search
, which will tell us what their engine actually collects.
[...] data is transferred to our search partners who only use it to provide better search results on Findx
So one "partner" wasn't enough, there had to be two - CodeFuel and Microsoft. FindX also shamelessly claims that Microsoft values your privacy
- can you believe it? Anyway, what is
the data being sent?
IP address, user agent string, search term, country and language settings, filter settings for adult content, active search filter settings (e.g. page number information), an optional Bing ID (read more below) and the ID of the organization that should benefit from your search.
So the privacy-respecting FindX shares pretty much everything possible with not one, but two third parties! Do they have an explanation for that? Sure they do - but I'm warning you - this will be one of the most idiotic things you've ever read on the Internet. Better wear a helmet, because the stupidity beam is coming!
"But you still pass on my IP-address to CodeFuel and Bing". Yes, we have to. We protect your privacy to the maximum extent allowed under the agreement we have with them. Other privacy-centric search engines mask part of your IP-address before passing it on to their partners - we are not allowed to do that. It is a matter of trust. You have to trust that the privacy search engines do not pass on your full IP-address to their partners. On Findx, you have to trust that our partners only use it for what thay say they will, which is to provide better results on our site (only) - nothing else. We trust them.
Wow, I've been hit with a hurricane of nonsense and I'm so confused I don't even know where to start with this. They literally admit to being worse than all other search engines - since those
(such as Swisscows or StartPage) actually limit the data sent to the providers they use. FindX just says fuck that and dumps all your info onto Bing, then tells you to
just trust their partners to honor an agreement that is never really specified aside from vague claims of "better search results". Sounds dangerously close to Mozilla's improve your experience
while they abuse all your data. And why would Microsoft submit to some small fry like FindX? It's more likely they just do whatever the fuck they want with your
stuff. What about the other partner, CodeFuel?
When search results are displayed, tracking pixels reveal to our search partner which of the results and ads we received were actually seen by you. Our partner, CodeFuel, solely uses this information for building metrics for us and statistics about the service usage. The information is not sold or shared with advertising companies. It simply provides us with information about earnings and various statistics like how many searches resulted in display of ads, how many unique users performed searches, how many results were clicked on etc.
So, FindX assures us that the data collection of CodeFuel is pretty mild. But their privacy policy (archive) tells a different story:
Certain usage related information regarding your use and interaction with your device, including the Software & Services and Other Software, such as when and how you Use the Software & Services and Other Software, how you use your internet browser and internet search related applications, your language settings, the web pages you visit, applications you use and the content you see, access and utilize on such web pages and applications; for example, offerings and advertisements that you view, use and access, how you use them and your response to them (ie. clickstream data), how frequently you use them, your search queries and the non-precise location, time and date of your searches
Even though FindX explicitly claims in their FAQ (archive) that this data is not shared with third parties...
CodeFuel acts as a 'middle-man' between small to medium-sized partners and Microsoft, and passes the data on to them in order to serve search results and ads. CodeFuel uses this information themselves to build metrics and statistics about the service usage. The information is not sold to or shared with anybody
CodeFuel does directly state several times that they do so:
In performing fraud detection and prevention, we use the services of third parties who will receive and access your PII.
We also use your PII to comply with legal and regulatory requirements [...] For this purpose, we may share your information with law enforcement or other competent authorities and any third party [...] We will also share this information with our professional advisors in the scope of this purpose.
We may also share your information with our subsidiaries, affiliated and parent companies pursuant to the legitimate interest for the provision of the Software & Services to you but their use of such information must comply with this Privacy Policy.
So two "partners" turned into who the fuck knows how many. There is way more dirt on FindX - their website also collects a bunch of data, TOS pretty much makes you a slave, etc. But I don't want to spend more time on this shitty search engine than absolutely necessary. Needless to say, it's not at all private and in fact, it's probably better to use Bing directly since FindX sends everything there anyway while also running their own spy operation (not to mention CodeFuel and their partners also laying their dirty hands on your data). This is probably the most dishonest search engine out there, rivaling VFEmail and Hushmail in their shamelessness.
So, the first edition of this summary was overly positive. I was eager to finally share some good news after the stuff on Mozilla, Proton, and others dirtied the privacy climate. However, I severely overestimated the situation and way overrated several search engines such as StartPage, MetaGer and DuckDuckGo. The main issue is that all of them lack their own index, meaning they are fully dependent on the violators. The ones who do use their own index have weak results. This already proves that the situation is worse than with browsers (which has the independent Pale Moon as well as various other smaller, less viable projects) or E-mail. Not only is there no provider approaching the quality of RiseUp mail - but even the second-tier of E-mail providers (such as Posteo or Dismail) outclass the best search engines. The field is also rife with frauds, similar to E-mail. What's a poor user to do, then? It would be best to pull the plug and deal with the inconvenience of terrible results, though of course it's hard to actually do that. However, the situation won't improve until we support the independent search engines. So, use Mojeek and Wiby to accomplish that. If you're not prepared to ditch the violators, a good SearX instance is your best bet. It is sad how, for most of them, the results still do not go beyond the first page (illustrating the failure of FOSS movement). I recommend weaning yourself off Google since they're so heavily censored, therefore StartPage is out. The wounded privacy warrior marches on, scraping by until a decent provider finally comes along...
| Engine / Feature | Swisscows | SearX | StartPage | Wiby | DuckDuckGo | Qwant | Metager | Mojeek | Ecosia | Oscobo | Discrete Search | Gibiru | Peekier | FindX |
| Requires JavaScript | Yes | No | No | No | No | Yes | No | No | For images | For images | Yes | Yes | Yes | No |
| Own index | No | No | No | Yes | Partial | Partial | No | Yes | No | No | No | No | No | No |
| Has onion domain | No | Conditional* | No | No | Yes | No | Yes | No | No | No | No | No | No | No |
| IP storage | No | Conditional* | No | Yes | Yes | Possible | Yes | No | Yes | Unknown | Yes | No | No | Possible |
| Search results | Average | Average | Good | Bad | Good | Good | Average | Bad | Good | Average | Good | Unknown (google scripts, no thanks) | Average | Good |
| Shares data with third parties | Yes | No | No | No | No | No | No | No | Yes | Yes | Yes | Yes | Yes | Yes |
Explanation of issues: